
Introduction to Text Preprocessing
Text preprocessing is a critical first step in the NLP pipeline. It involves preparing and cleaning text data before it can be effectively used for analysis and machine learning models. The primary goal of text preprocessing is to strip away noise and inconsistencies in the raw data, thereby increasing the quality of the data input into NLP algorithms.
Key Steps in Text Preprocessing
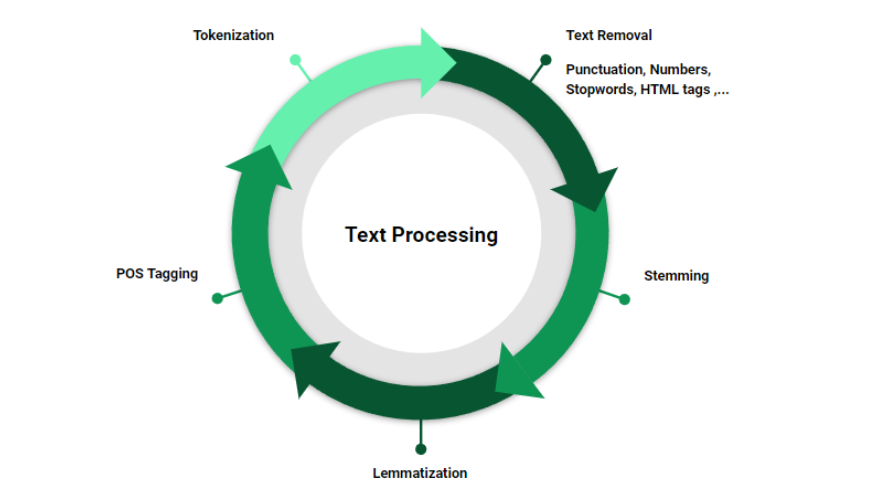
1. Tokenization: This is the process of breaking down a string of text into smaller pieces, called tokens. Tokens can be words, phrases, or sentences. Denis Rothman details a practical approach to tokenization using libraries like NLTK, where text is first converted into a continuous string without newlines and then tokenized into words.
2. Lowercasing: Once tokenized, converting all the tokens to lowercase ensures that the algorithm does not treat words like “Apple” and “apple” differently, which is critical for maintaining consistency and reducing the vocabulary size.
3. Removing Stop Words: Common words such as “and”, “is”, and “in”, which may not contribute meaningful information to certain NLP tasks, are often removed. This step is contingent on the specific requirements of the project as sometimes stop words are necessary for maintaining sentence context.
4. Stemming and Lemmatization: These techniques reduce words to their root form. Stemming might reduce the word “running” to “runn”, while lemmatization would correctly convert it to “run”. Rothman emphasizes the use of lemmatization over stemming to retain semantic meaning of the words in the processed data.
5. Removing Punctuation and Special Characters: Non-alphanumeric characters and punctuation are generally removed to reduce potential noise in the text data. This includes html tags, which are prevalent in data scraped from the web.
6. Handling Emoticons and Special Sequences: In contexts like sentiment analysis, emoticons or special character sequences such as “:-)” may convey important sentiment information and are thus retained and separately processed.
Advanced Techniques
1. Subword Tokenization: This involves breaking words down into smaller units (subwords) to help deal with unknown words during analysis. This technique is useful for languages with rich morphology and compounding like German or for processing programming code.
2. Use of Regular Expressions: Regex can be a powerful tool for specific text cleaning tasks, such as removing specific patterns or extracting all occurrences of a complex string pattern.
Practical Applications and Considerations
Preprocessing techniques must be adapted for the specific context of the application. For instance, in sentiment analysis, emoticons may carry significant weight, whereas, in legal document analysis, the precise use of language is crucial, and simplistic stemming may be inappropriate.
Conclusion
Effective text preprocessing improves the performance of NLP models by creating a cleaner, more uniform dataset that more accurately represents the underlying data. As described by Rothman, the preprocessing steps should be carefully chosen to align with the goals of the specific NLP application, ensuring that valuable information is not inadvertently stripped away during the cleaning process.
This overview provides a robust foundation for understanding and implementing text preprocessing, which is critical for any NLP practitioner looking to enhance the quality and reliability of their machine learning models.